Your feedback is highly appreciated! Let's make Vertabelo even better.

 SQL basics quiz problem
SQL basics quiz problem
Hello,
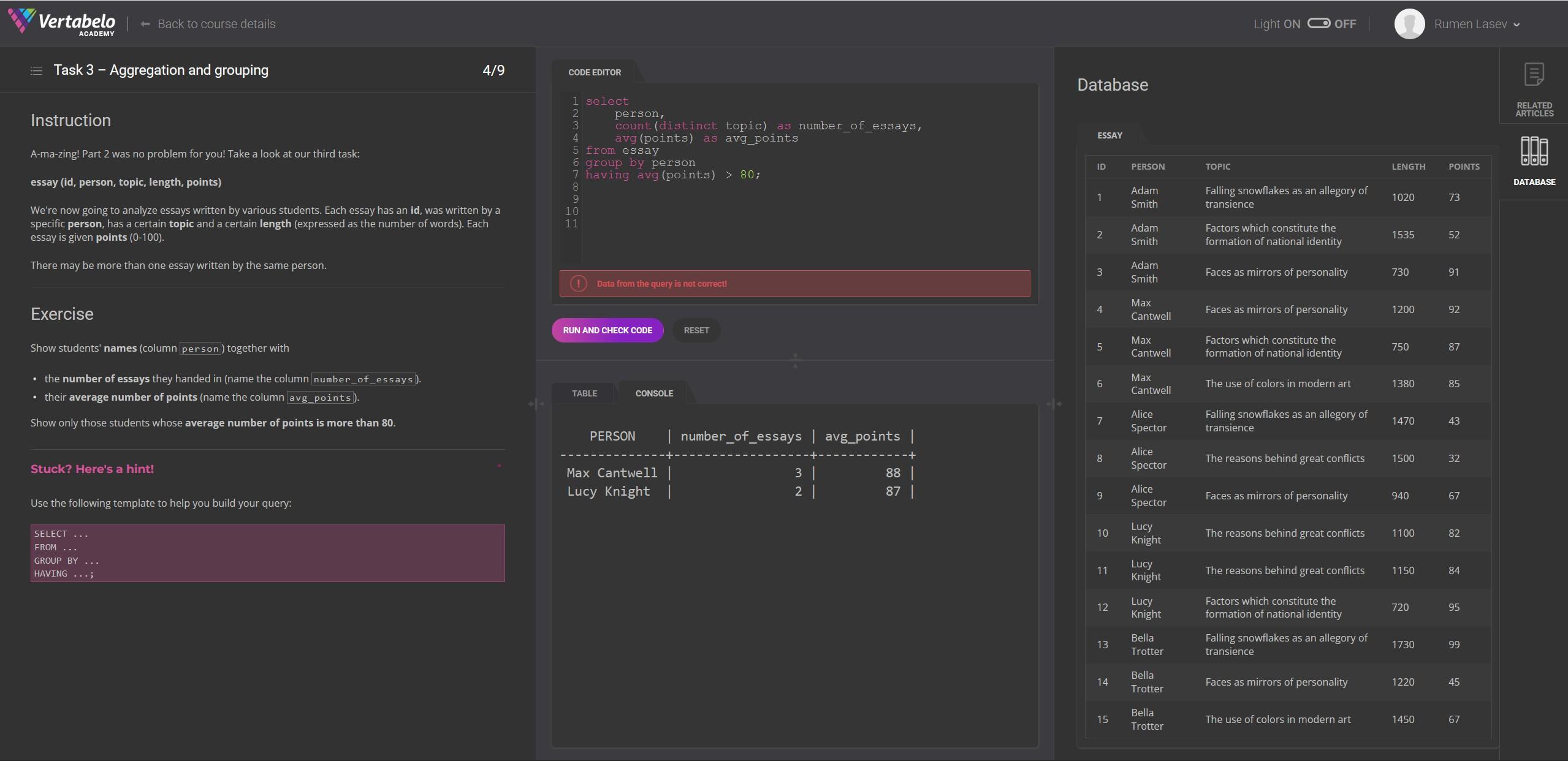
Could anyone please tell me why this asnwer is not being accepted? I find it ridiculious that I can't find any way to see what the actual answer is because I see no reason why this would be incorrect.
Thank you.

How to define identifying or non-identifying relationship in Vertabelo?

PDF generation problems


 Add support for right-click context menu
Add support for right-click context menu
It would be awesome to be able to right-click and see a menu that allows a user to add a new table / relation / etc. instead of having to go to the sub-nav menu and drag one of them out onto the canvas.
Hello,
If you click on an item in the sub-nav menu then this item indicates default behaviour of left-click action.
For example, if click on the 'add new table' icon then after every click on the diagram new table will be added (until you change it). How to add a table

Every item has related number (e.g. add new table - 3). You can switch between them by pressing this number on a keyboard.
I think our solution is easier when it comes to batch adding and that's way we chose it.
I will keep the issue open so the other users can upvote and comment of this feature.

Graphical representation of UNIQUE columns
Why isn't there a "U" on the right side next to type like there is a graphical representation for private and foreign keys? I know you can set a variable as unique but it doesn't show in the diagram.
Import of table and column descriptions from SQL not working
I need to migrate over existing model with 150 tables from another tool to vertabelo along with descriptions through SQL export-import? Right now tables are getting imported but no table descriptions or column descriptions are imported. How to do that?

Hi,
I assume you want to use an academic account on Vertabelo.
You can create an academic account providing a scan of your ID card. You do not have to provide an academic email address. In the registration form, next to the field 'ID card scan', select the image from your local disk.
I hope that helps,
Mariusz Zakrzewski
Does Vertabelo offer database plans or just design services?
Do I need a third-party database service?
or ...
Does Vertabelo offer database plans?
Thanks Anyway,
- Emanuel Messias, R.d.S (Brazil)
Customer support service by UserEcho
