Your comments
We consider to add such possibility. So I keep the issue open for comment and vote by other users.
11 years ago
I guess that you mean about results you get after click on "Preview SQL" button.
We don't show foreign keys because it is a part of different diagram element - Reference. This behaviour is intentional.
We don't show foreign keys because it is a part of different diagram element - Reference. This behaviour is intentional.
Subject areas and possibility of changing colors of diagrams elements are the only elements designated to manage visual side of the model.
The color of model area is a part of the whole Vertabelo visual design and it has to correspond to others elements - panels, controls, grid etc.. So we don't plan to add user possibility of changing it (however it is very simple from implementation point of view).
The color of model area is a part of the whole Vertabelo visual design and it has to correspond to others elements - panels, controls, grid etc.. So we don't plan to add user possibility of changing it (however it is very simple from implementation point of view).
You can also use subject areas feature to surround particular tables. Subject area can have background itself, so you can set background color not for the whole model but a part of it.
You are right. Setting colors for many objects on diagram is not comfortable. I think we can improve this by allowing users to change format properties for all selected objects. We will put it on our road map of UI/UX enhancements.
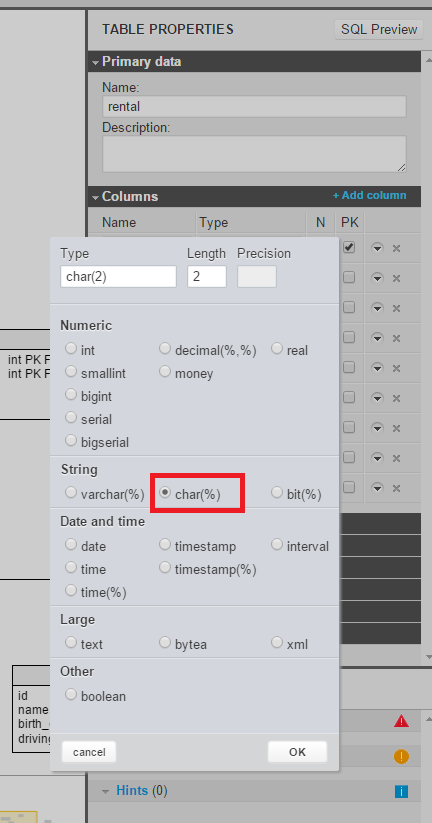
Char type is supported by Vertabelo. You can type it manually or choose from the column type selector. See following picture:
Amazon Redshift is based on PostgreSQL and as its documentation states you can use PostgreSQL JDBC drivers to connect to database. This way you can use our reverse engineering tool that can connect to your database and extract schema information to Vertabelo XML file. Then you should create empty database model in Vertabelo (choose PostgreSQL engine) and import XML file. Here you find detailed instruction how to use our reverse engineering tool:
https://www.vertabelo.com/blog/documentation/reverse-engineering
The second option you can try is dumping your database schema to sql file and import it directly into Vertabelo (we have import from SQL DDL feature). But I'm not sure if pg_dump works well with Amazon Redshift.
We don't test Vertabelo with Amazon Redshift but it should work.
https://www.vertabelo.com/blog/documentation/reverse-engineering
The second option you can try is dumping your database schema to sql file and import it directly into Vertabelo (we have import from SQL DDL feature). But I'm not sure if pg_dump works well with Amazon Redshift.
We don't test Vertabelo with Amazon Redshift but it should work.
The biggest format that we suppport now is B2 (500x707mm). In your case choosing that format give you about 10 pages and I hope reduce your pain. Unfortunately we can't support bigger format at this moment due to some performance problems.
Review of PDF print implementation is scheduled for January 2015. Stay tuned.
Review of PDF print implementation is scheduled for January 2015. Stay tuned.
You can use public link functionality instead of sharing model in such case. You can set it on model details screen.
In Vertabelo we would like to concentrate on ER modeling. Diemensional modeling is not planned.
Customer support service by UserEcho

